最佳答案 必须返回对象时,别妄想返回其 reference 学习了前面的章节之后,我们明白了 pass-by-value 和 pass-by-reference 的区别之后,我们往往会想优化自己的代码,把原先自己...
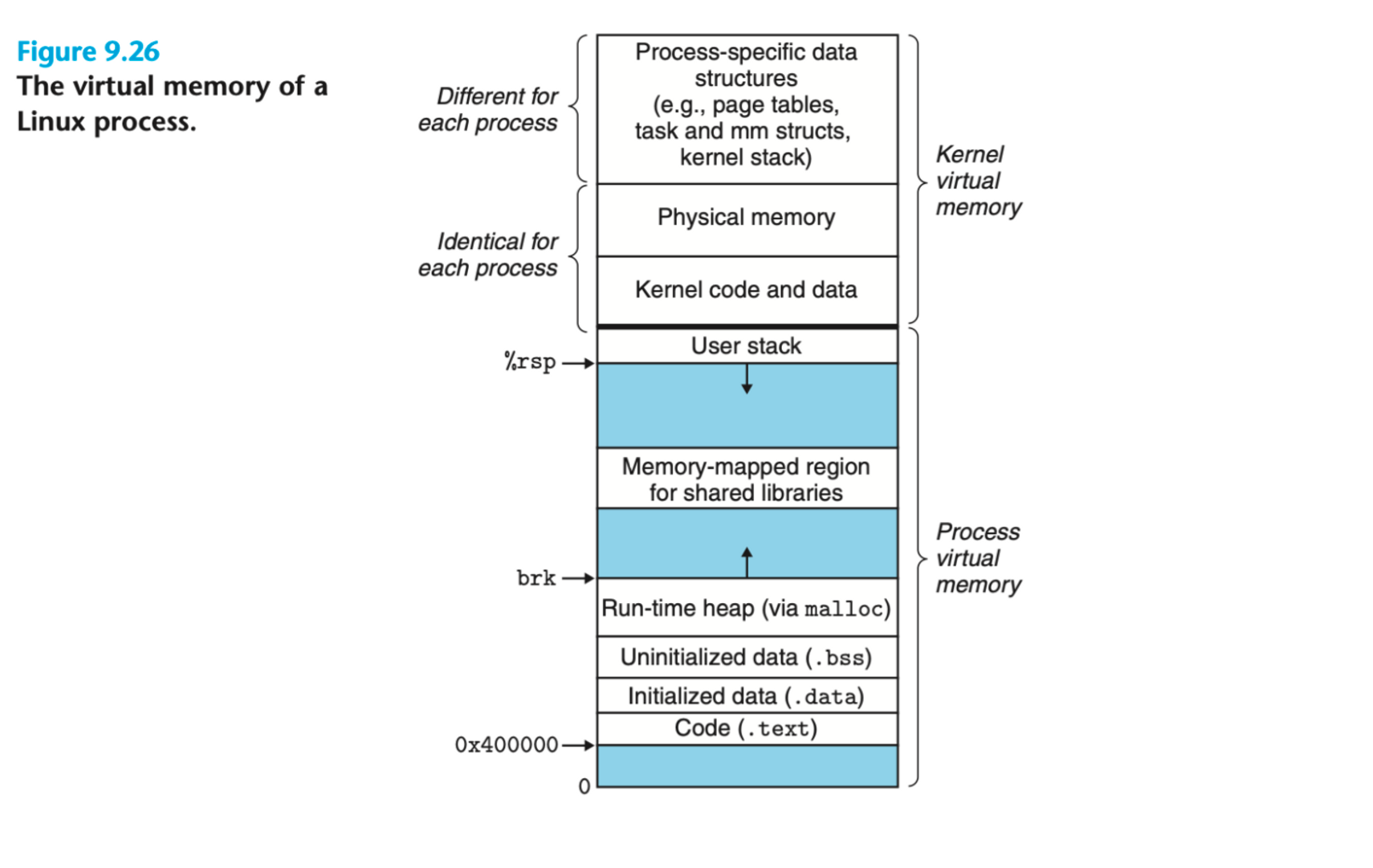
学习了前面的章节之后,我们明白了 pass-by-value 和 pass-by-reference 的区别之后,我们往往会想优化自己的代码,把原先自己会写 pass-by-value 的地方全都替换为 pass-by-reference ,但是如果你对 stack 和 heap 的理解不够的话,盲目的使用 pass-by-reference 会造成巨大的错误。下面是一张 X86-64 下 Linux 机器的虚拟空间图(来自 CSAPP 9.72)
User stack 由高地址向低地址增大,Run-time heap 由低地址像高地址增长,C++ 中的 new 和 delete 操作底层实际也是调用了 malloc 和 free 函数。函数中没用 malloc、new 创建的对象都是临时对象(局部变量),存放在 stack 中,由操作系统管理,用 malloc、new 创建的对象存放在 heap 中,由程序员自己手动管理,依靠 C++ 类的析构函数也被认为是程序员管理。
下面给出一个 case 1
第二十章总结过,传参数为 内置类型、STL 迭代器、函数对象 的时候,pass-by-value 比 pass-by-reference ,本例子不是为了讨论谁更高效,是为了说明两个情况是否程序能够正常运行。
case 1 中 pass-by-value 能够正确运行,但是 pass-by-reference 就不行,因为 fun2 在执行 return 之前,会先计算 a*b 并存为一个临时变量 temp,返回临时变量(return temp)。这个 temp 就是存储在 stack 中的(没有用 new、malloc 创建),由操作系统管理,所以在 fun2 结束之后,temp 的空间就被释放了(栈指针 %rsp 移动了,但是原先的内容没有销毁)。而 fun2 是返回索引,也就是依靠地址寻址,这个地址又被释放了,所以程序会出错。
内存模拟图
如上图所示,fun2 结束之后,返回的是 temp 所在的地址 0x100 ,但是 %rsp 已经退回, temp 的空间已经释放,如果有其他临时变量产生,0x100 这个地址的内存就会被覆盖,导致程序进入不可知状态。
下面是 case 2
case 2 不会运行出错,但是会造成内存泄漏,因为没有代码来 delete tmp;,如果把这个任务丢给客户显然不合适,这就给了客户犯错误的机会。
下面使用 static 的方式给出 case 3
使用 static 变量可以既可以使用 pass-by-reference 也可以解决内存管理的问题,但是也有其他问题
这段代码执行之后会发现,执行的其实是 choice 1,这不难理解,因为 fun2 是返回引用,fun2(1,1)和 fun2(2,2)返回的地址实际上是同一个地址,执行 if 判断之前要先执行 fun2(1,1) 和 fun2(2,2),fun2(1,1) 会将 tmp 赋值为 1,再执行 fun2(2,2) 会把 tmp 赋值为 4,再执行 if 判断的时候实际上执行的是 if (4 == 4)…。自然只能是相当,然后执行 choice 1 的代码。也会有人想声明一个 static 数组专门来存放计算的数据,但是这个数组的大小设置又是难题。
绝不要返回 pointer 或者 reference 指向一个 local static 对象,或返回 reference 指向一个 heap-allocated 对象,或返回 pointer 或 reference 指向一个 local static 对象而有可能同时需要多个这样的对象。
必须返回对象时,别妄想返回其 reference
//以前的写法 pass-by-value
int fun1(int a,int b){
return a*b;
}
//现在的写法 pass-by-reference
int& fun2(const int& a,const int& b){
return a*b;
}

int& fun2(const int& a,const int& b){
int* tmp = new int (a*b);
return *tmp;
}
int& fun2(const int& a,const int& b){
static int tmp = a*b;
return tmp;
}
if( fun2(1,1) == fun2(2,2)){
// ... choice 1
}else{
// ... choice 2
}
总结:
